















인공지능(AI)에서 말하는 데이터셋(dataset)이란, 기계가 학습을 하는데 필요한 데이터의 집합이다. 좋은 인공지능을 위해서는, 해당 영역에서 고품질 데이터를 모아놓은 학습 데이터가 필수이다. 양적, 질적으로 우수한 데이터셋을 학습한 AI는 편향되지 않으며, 정확도가 높은 결괏값을 만들어낸다.
예를 들어, 바둑 알고리즘을 학습해 바둑 천재 이세돌을 이긴 AI '알파고'는 KGS공개서버에서 운영된 바둑 게임 데이터를 사용했다. 이 중에서도 고수(6단-9단)의 게임만을 사용했으며, 16만 개에 달하는 데이터로 학습했다.
안면인식 AI의 데이터 학습
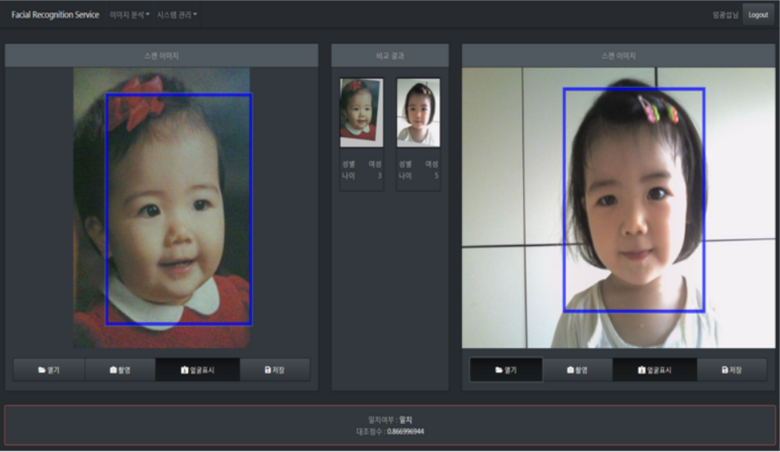
인공지능을 기반으로 개발된 안면 인식 기술은 최근 비약적 발전을 거쳐, 기존 출입 통제나 범죄 수사뿐만 아니라 금융 결제 및 영상분석 영역까지 확대되고 있다.
그런데, 사람의 얼굴을 판독하는 AI에는 어떤 데이터셋을 사용해야 할까? 예시에 사용된 AI 허브의 '안면인식 응용 서비스' 원본 데이터는 600명의 한국인에게서 인당 32,400장의 이미지를 추출하였고, 총 1900만여 장의 데이터로 이루어져 있다. 포즈 방향, 조명 위치 및 세기, 표정, 해상도 등을 기준으로 분류, 설계된 데이터 베이스이다.
아기의 얼굴을 인식하려면 아기 얼굴 이미지가, 한국인의 얼굴을 인식하려면 한국인 얼굴 이미지가 필요하다. 다양한 연령, 인종만큼이나 다양한 안면 데이터셋. 이 중 몇 가지를 추려 살펴보자.
1. The Asian Face Age Dataset (AFAD)
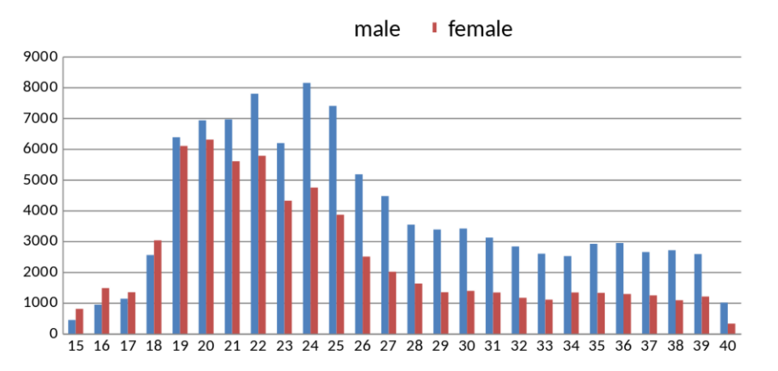
아시아인의 얼굴을 보고 연령 추정을 위해 만들어진 데이터이다. 모든 데이터는 아시아인의 사진으로 구성됐다. 현재까지 존재하는 가장 큰 데이터셋으로, 16만 개가 넘는 얼굴 이미지와 함께 사진 속 인물의 연령, 성별 라벨이 포함되어 있다. 남, 여 구성비는 약 5:3이며 연령대는 15세에서 40대까지 다양하다.
기존 연령 추정을 위한 공개 데이터로 FG-NET (1002개의 얼굴 이미지), MORPH1(1690개의 얼굴 이미지) 및 MORPH2(55,608개의 얼굴 이미지) 등이 있었으나, 아시아 얼굴에 특화된 형태로 새로 제안되었다. 저자는 Zhenxing Niu, Mo Zhou, Xinbo Gao, Gang Hua 이다.

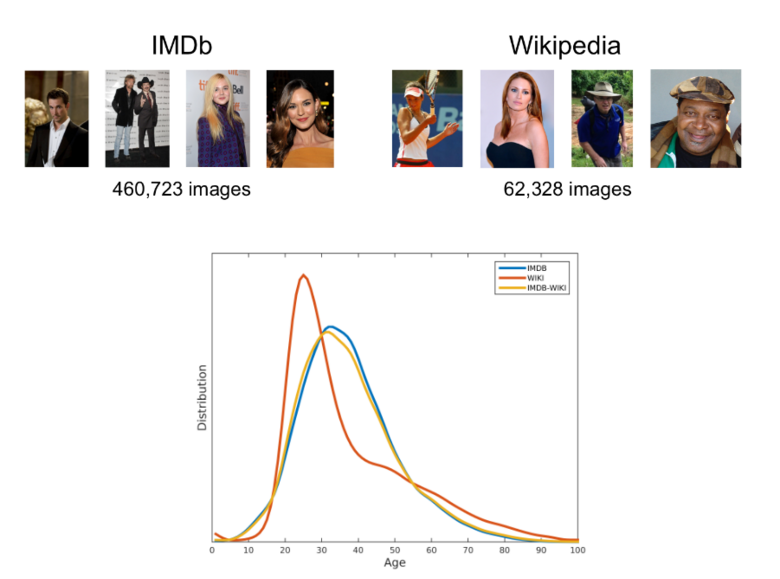
2. IMDB-WIKI
2015년, '연령 추정에 대한 LAP 챌린지'에서 우승한 데이터셋으로, 단일 이미지의 연령 추정을 위해 만들어졌다. 공개된 유명인의 이미지를 IMDb에서 약 46만 개, 위키피디아에서 약 6만 개 크롤링하여 총 50만 개의 데이터셋을 구축했다.
IMDb는 가장 인기 있는 10만 명의 배우 목록에서 생년, 이름, 성별 및 관련 이미지를 크롤링하였고, 동일한 방식으로 위키피디아의 사용자 프로필 이미지를 크롤링했다. 저자는 Rasmus Rothe, Radu Timofte, Luc Van Gool 이다.
3. Diversity in Faces (DiF)
2017년, 영국 UEFA 챔피언스 리그 결승전 당시 웨일즈 경찰은 자동 얼굴인식 시스템을 기반으로 범죄용의자를 탐지하겠다는 계획을 세웠다. 하지만, 경기 당일, 시스템은 2,470명에 달하는 사람을 용의자로 지목했으며, 이 중 약 92%가 오인식이었다.
이러한 오인식의 원인으로 얼굴인식 시스템의 편향성을 언급할 수 있다. 또, 이와 관련, 실제로 아프리카계 미국인은 백인보다 5~10% 정도 정확도가 떨어진다는 연구 결과도 있다.
DiF는, 얼굴 인식 기술의 공정성과 정확성 향상을 목표로 IBM 기초연구소에서 2019년 공개한 얼굴 데이터셋이다. 연구팀에 따르면, 실제 얼굴 인식 시스템 성능에 영향을 미치는 것은 '내재적 얼굴의 다양성' 이지, 인식 정확도가 개인이나 집단에 따라 달라질 수는 없다는 입장이다.
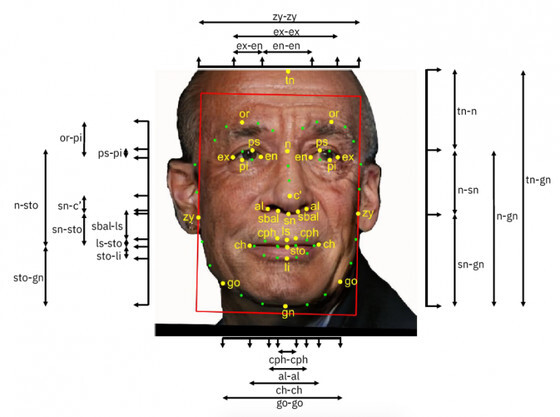
데이터셋에는 약 100만 명의 얼굴 데이터가 포함돼 있는데, 각 이미지에는 머리 모양과 얼굴의 대칭, 코의 길이, 이마 높이 등 객관적 얼굴 척도와 함께 연령과 성별 등 주석이 라벨링 되어 있다. 얼굴 부위 47곳 이상의 크기, 특징을 정리해 놓았으며 이와 같은 특징이 알고리즘의 성능을 강력하게 만들고 시스템 공정성, 정확성을 향상시키는 요인이 된다고 한다.
[저작권자ⓒ CWN(CHANGE WITH NEWS). 무단전재-재배포 금지]








![[구혜영 칼럼] 사회복지교육은 미래복지의 나침반이 되어야](/news/data/2026/01/16/p1065596364370517_157_h.png)





